24. Understanding Nucleic Acids: A Complete Guide to DNA and RNA
Have you ever wondered how a tiny, invisible molecule can hold the vast instruction manual for an entire human being? The secret lies in the elegant structure of our genetic material. This slide deck breaks down the structural biochemistry of these vital molecules. By exploring everything from basic nucleotide monomers to complex replication processes, this guide provides college and medical students with a clear, comprehensive understanding of how genetic information is stored, transmitted, and utilized in living systems.
Slide 1 – Introduction to Nucleic Acids: The Molecular Architects
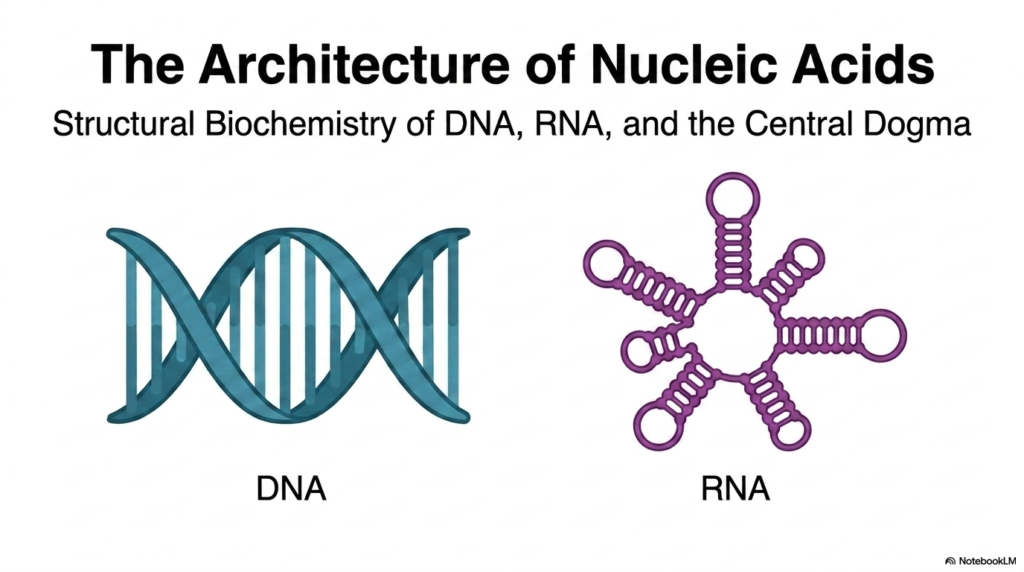
DNA and RNA are the foundational molecules of life, serving as the ultimate architects of biological systems across the entire globe. When we study the structural biochemistry of these macromolecules, we are essentially reading the intricate, microscopic blueprint of cellular existence. These incredibly complex polymers, universally recognized as Nucleic Acids, bear the heavy responsibility of storing, safeguarding, and transmitting the precise genetic information required for every single living organism to function, adapt, grow, and faithfully reproduce. Grasping their fundamental molecular architecture is absolutely paramount and serves as the crucial first step for any university student entering the rigorous fields of modern biochemistry, genetics, or molecular biology.
The immediate visual distinction between the two primary classes of these essential molecules is stark and biochemically significant. Deoxyribonucleic acid typically forms a highly rigid, deeply intertwined double-stranded helix. This robust configuration perfectly suits its evolutionary role as a highly stable, long-term storage vault for life’s precious genetic codes. In sharp contrast, ribonucleic acid frequently presents as a highly flexible, single-stranded molecule that can eagerly fold into a dazzling array of highly intricate, versatile shapes. This remarkable structural flexibility allows these specific Nucleic Acids to perform a wide array of complex cellular functions, from carrying transcribed messages to actively catalyzing vital chemical reactions in the cellular cytoplasm.
By rigorously analyzing the overarching structural biochemistry of these biological polymers, we begin to unlock the deepest secrets of the Central Dogma of molecular biology. This foundational concept explains the strict, unidirectional flow of genetic information from stable genomic databases to functional cellular machinery. Throughout this comprehensive exploration, we will meticulously dissect the specific molecular bonds, complex atomic interactions, and intricate three-dimensional conformations that give these particular Nucleic Acids their incredible, life-sustaining capabilities. Mastering this foundational chemical architecture is entirely essential for understanding exactly how complex biological life operates and thrives at the most fundamental, microscopic level known to modern science.
Slide 2 – The Central Dogma and the Information Flow of Nucleic Acids
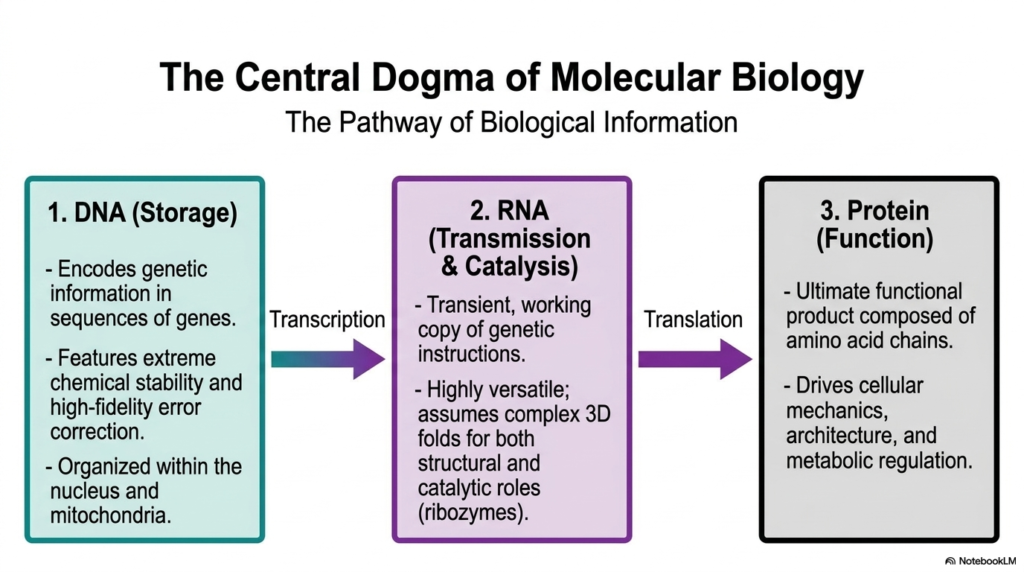
The Central Dogma of molecular biology beautifully illustrates the vital, highly regulated flow of biological information, clearly highlighting the distinct roles of different molecular polymers. At the absolute starting point of this complex biochemical pathway is the double helix, which functions as the ultimate, secure storage center. This primary class of Nucleic Acids rigorously encodes highly complex genetic information within their long gene sequences. It is brilliantly characterized by extreme chemical stability and incredibly high-fidelity error correction mechanisms, meticulously ensuring that life’s fragile instructions are preserved safely and accurately within the protective confines of the cellular nucleus and energy-producing mitochondria.
The very next critical step in this biological assembly line involves transcription, in which the tightly guarded information stored in the genome is carefully converted into a highly transient, mobile working copy. This second distinct class of Nucleic Acids is entirely responsible for intracellular transmission and active catalysis. It is highly versatile; it is not merely a passive, simple messenger but can actively assume incredibly complex three-dimensional folds. These intricate folds allow these mobile Nucleic Acids to take on vital structural roles and even act as powerful enzymes, known as ribozymes, capable of independently driving essential cellular reactions.
Finally, the critical information carried by these intermediate messenger molecules undergoes a complex process called translation, ultimately producing functional proteins, the true, hard-working products of the living cell. Proteins, which are completely composed of massive, folded chains of distinct amino acids, are the heavy-lifting workhorses that actively drive nearly all cellular mechanics, build robust cellular architecture, and intricately regulate complex metabolic pathways. The Central Dogma elegantly demonstrates how the invisible genetic storage and transmission governed by Nucleic Acids ultimately manifest as visible physical traits, orchestrating the incredibly complex, highly synchronized, and beautiful symphony of biological life.
Slide 3 – Primary Structure: The Monomeric Foundations of Nucleic Acids
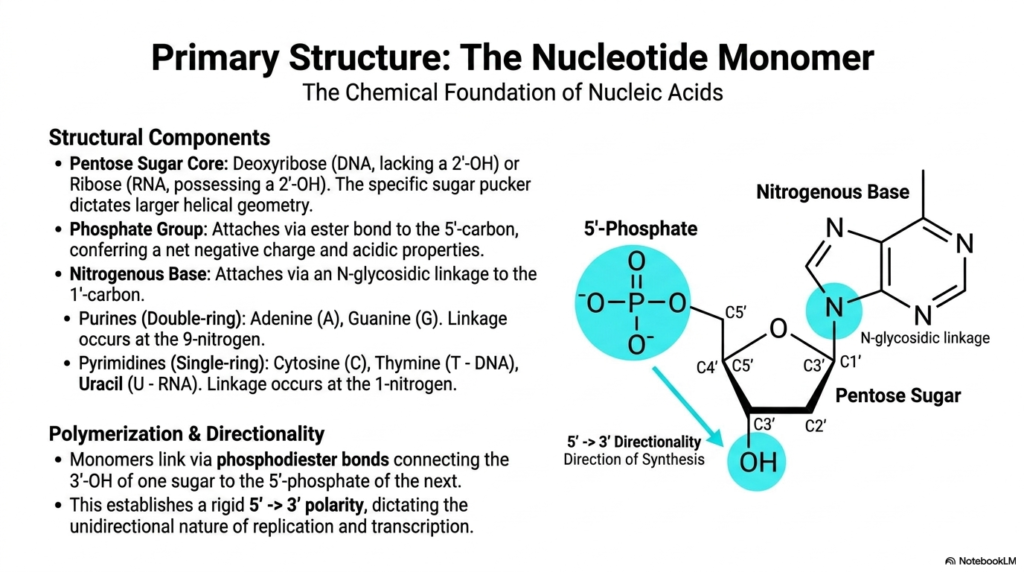
To truly and deeply grasp the staggering complexity of biological life, we must first rigorously examine the fundamental structure of these vital macromolecules, starting with their most basic building block: the nucleotide monomer. Every single independent nucleotide consists of three highly specific structural components. The central core is always a pentose sugar ring, which is deoxyribose in genomic storage or ribose in messenger molecules. The presence or absence of a highly reactive hydroxyl group on the 2′-carbon of this sugar precisely dictates the overall helical geometry and stability of these Nucleic Acids.
Firmly attached to this foundational sugar core is a crucial phosphate group, tightly connected via a strong ester bond located specifically at the 5′-carbon position. This particular phosphate group is chemically vital because it permanently confers a strong net negative charge and highly acidic properties to all physiological Nucleic Acids. The third mandatory component is a distinct nitrogenous base, strongly attached to the 1′-carbon via a highly specific N-glycosidic linkage. These specific bases are carefully categorized into large, double-ringed purines, like adenine and guanine, and much smaller, single-ringed pyrimidines, such as cytosine, genomic thymine, and the exclusively messenger-bound uracil.
The true functional magic of these molecular building blocks occurs during the complex process of polymerization, where numerous individual monomers permanently link together to form incredibly long, unbroken chains. They are tightly connected via robust phosphodiester bonds, firmly bridging the 3′-hydroxyl group of one sugar ring directly to the 5′-phosphate of the next consecutive unit. This highly specific, rigid chemical bonding actively creates a sturdy backbone for these Nucleic Acids with a very distinct 5′ to 3′ polarity. This strict directionality is a fundamental chemical reality that entirely dictates the strictly unidirectional nature of critical biological processes like replication.
Slide 4 – Secondary Structure: The Classic B-DNA Form of Nucleic Acids
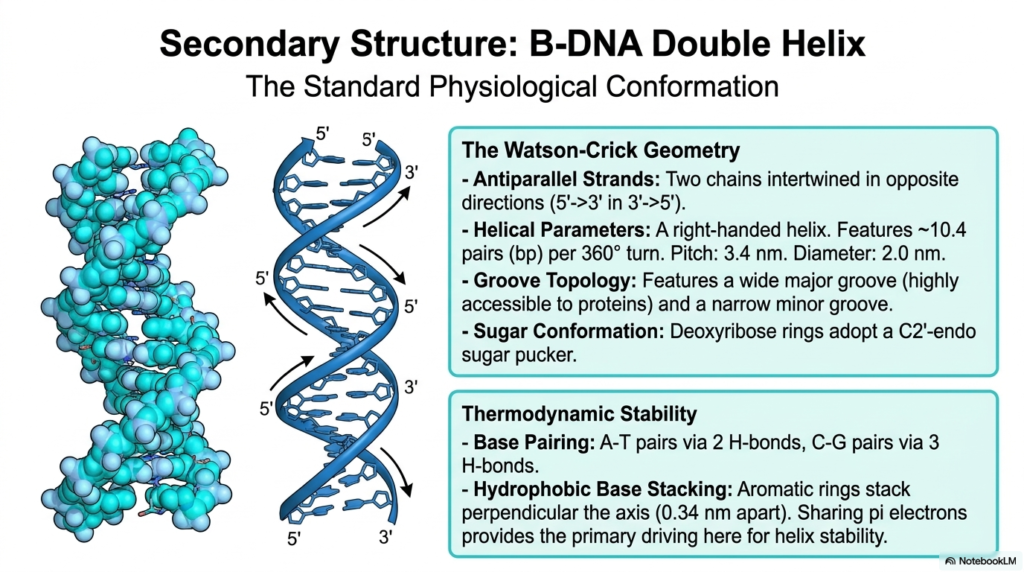
When we closely examine the broader secondary structure of these incredibly remarkable molecular polymers, the globally recognized, classic B-DNA double helix stands out as the absolute standard physiological conformation. This is the intensely famous, highly celebrated structure originally discovered by Watson and Crick, which perfectly characterizes the most common biological form of these vital molecules, actively found thriving in healthy, living cells. The precise geometry clearly features two entirely separate, antiparallel strands, meaning the long polymeric chains are deeply intertwined but run in opposite directions, with one strand running 5′ to 3′ and the complementary strand running 3′ to 5′.
This highly regular, distinctly right-handed helical architecture of these universally essential Nucleic Acids is stunningly uniform, consistently featuring approximately 10.4 base pairs per full 360-degree molecular turn. Overall, the larger structural geometry directly produces highly distinct groove topologies that span the entire exterior surface of the helix. There is a remarkably wide major groove that is readily accessible and naturally serves as the primary binding site for crucial regulatory proteins. Additionally, there is a distinctly narrower minor groove. Furthermore, the central pentose sugar rings, securely locked in this specific conformation, typically adopt a highly relaxed C2′-endo sugar pucker.
The incredibly impressive, long-term thermodynamic stability of these particular, highly specialized Nucleic Acids relies heavily on two major chemical forces acting in tandem. First, incredibly strict, unyielding base-pairing rules absolutely dictate that adenine only pairs with thymine via two hydrogen bonds, while cytosine strictly pairs with guanine via three tightly bound hydrogen bonds. Second, and arguably far more critical for overall, long-term structural stability, is the powerful force of hydrophobic base stacking. The entirely flat, distinctly aromatic rings of the internal bases stack closely, completely perpendicular to the helical axis, sharing pi electrons and robustly stabilizing these enormous Nucleic Acids against destruction.
Slide 5 – Environmental Variations and Alternative Conformations of Nucleic Acids
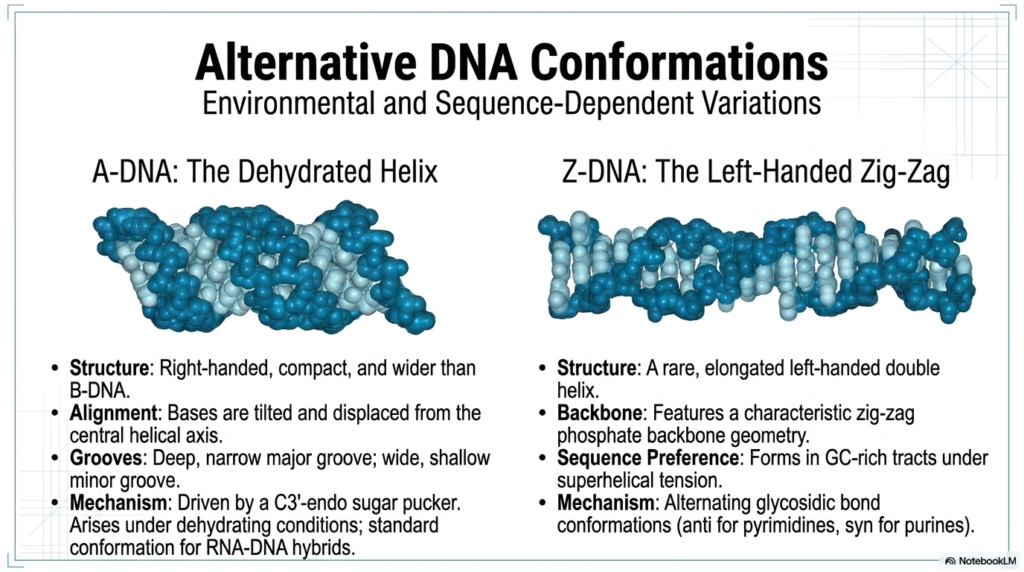
While the classic, highly recognizable B-form double helix is absolutely the most famous structural iteration, the primary genomic storage molecule is actually quite remarkably dynamic and can readily adopt distinct alternative conformations in response to severe environmental shifts and specific genetic sequences. One such notable structural variation is the A-DNA form, which typically forms only under severe dehydrating laboratory conditions. Compared directly to the standard, hydrated B-form, this alternative structure of these essential Nucleic Acids is a much more tightly compact, distinctly wider, and strictly right-handed helix. In this particular dehydrated state, the central base pairs are significantly tilted and displaced.
The massive structural and conformational shift clearly seen in A-form Nucleic Acids drastically and completely alters its exterior topological landscape. The major groove becomes incredibly deep and distinctly narrow, rendering it largely inaccessible, while the minor groove becomes exceptionally wide and noticeably shallow. This highly distinct, alternative shape is entirely driven by a fundamental atomic shift in the sugar pucker directly to a much tighter C3′-endo conformation. Interestingly, while the classic A-DNA double helix is considered relatively rare in standard, purely physiological, fully hydrated cellular environments, this exceptionally compact structural geometry is actually the standard, default conformation for temporary RNA-DNA hybrids.
Another completely fascinating, highly extreme deviation found in the complex world of these biological polymers is the remarkably strange Z-DNA. Unlike the universally right-handed A and B forms, Z-DNA is an incredibly rare, highly elongated, strictly left-handed double helix. Its exposed phosphate backbone features a highly characteristic, incredibly irregular, zig-zag chemical geometry. This bizarre structure typically forms only in isolated regions of Nucleic Acids that are uniquely rich in strictly alternating guanine and cytosine bases and are actively subjected to intense superhelical tension. It elegantly arises from an alternating, distinct pattern of anti and syn glycosidic bond conformations.
Slide 6 – Tertiary and Quaternary Packing Architectures of Nucleic Acids
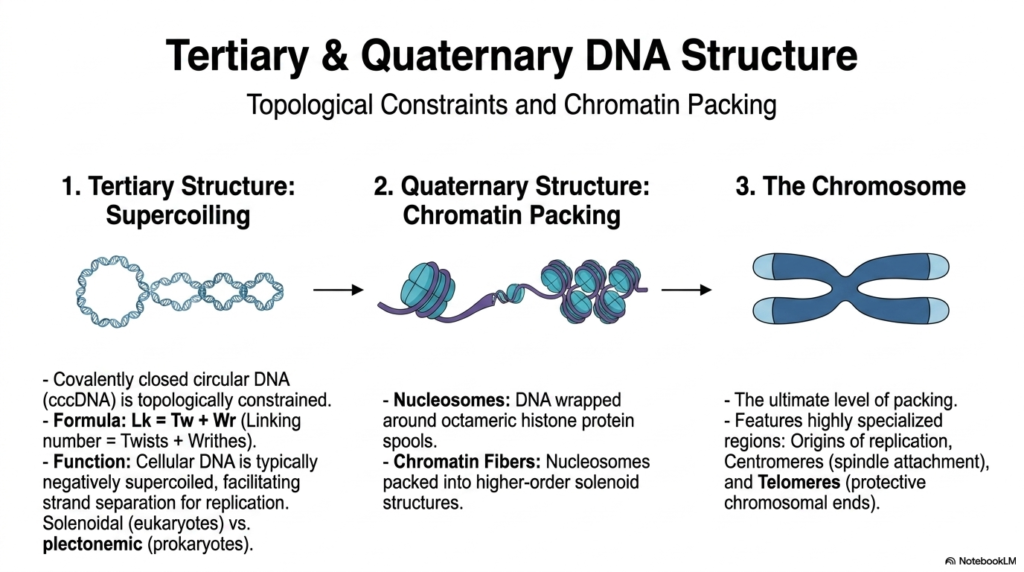
Beyond the beautifully simple, standard double helix, the sheer, unimaginable physical length of these vital genetic polymers absolutely requires intensely complex tertiary and quaternary structural architectures simply to fit completely within a microscopically tiny cell. For covalently closed circular genomes, which are extremely common in basic bacteria, the primary tertiary structure is characterized by intense supercoiling. Because the terminal ends of these specific Nucleic Acids are permanently joined, they face incredibly severe topological constraints strictly governed by a rigid mathematical formula directly linking the exact number of twists and writhes. Cellular genomes are actively and typically negatively supercoiled, thereby storing critical kinetic energy.
In far more complex eukaryotes, the necessary quaternary structure of these massive, sprawling Nucleic Acids relies heavily on an incredibly intricate, highly regulated system of dense chromatin packing. The raw, unbroken double helix is systematically and tightly wrapped directly around specialized octameric spools composed primarily of highly basic histone proteins, thereby forming fundamental structural units called nucleosomes. These numerous nucleosomes closely resemble small beads on a long string and are subsequently packed and twisted even tighter into massive, higher-order, incredibly dense solenoid structures. This incredibly meticulous, multi-layered organization perfectly prevents severe molecular tangling and strictly regulates which active genes are highly accessible.
The ultimate, most highly condensed form of physical packaging for these essential Nucleic Acids is the recognizable chromosome, which becomes fully visible only during active cellular division. Chromosomes are elegantly represented as highly condensed, distinct physical structures that safely and securely organize the entire genome. They notably feature highly specialized, uniquely structured regions absolutely crucial for their physical maintenance and accurate segregation. These distinct chromosomal regions actively include specific origins of replication where genomic copying safely begins, dense centromeres that serve as vital attachment points for pulling spindle fibers, and protective telomeres preventing the slow degradation of essential genes.
Slide 7 – Single-Stranded Complexity and RNA Paradigms of Nucleic Acids
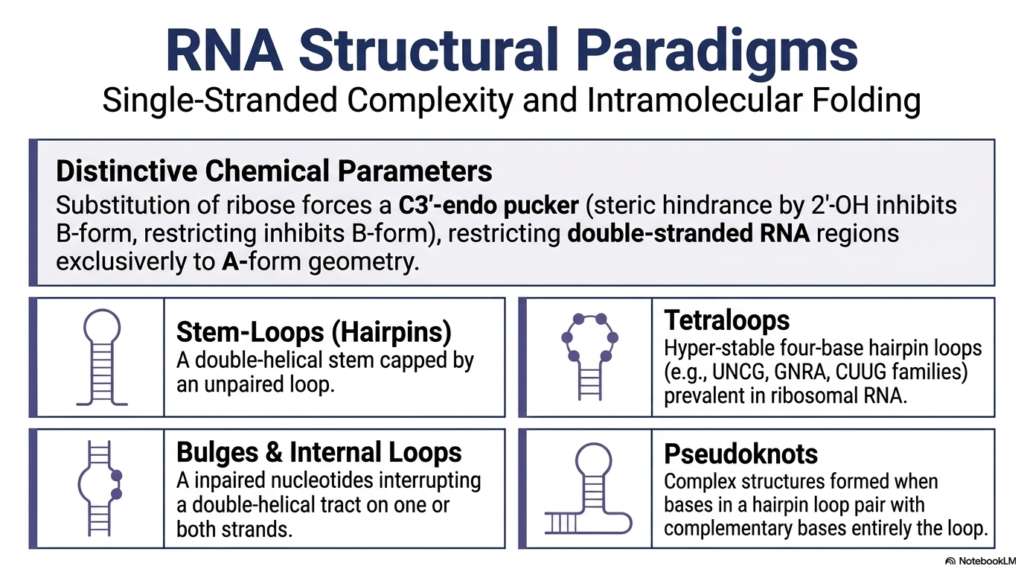
While the primary genomic storage vault is universally famous for its rigid double helix, the critically important second major class of these molecules is completely renowned for its remarkable single-stranded complexity and incredible, highly dynamic intramolecular folding capabilities. This immense structural diversity is deeply rooted in several highly distinct, unyielding chemical parameters. The fundamental substitution of standard deoxyribose for an oxygen-rich ribose sugar powerfully introduces a significantly bulky 2′-hydroxyl group into the backbone. This small addition creates an immense steric hindrance that completely prevents these particular Nucleic Acids from ever adopting the standard B-form, thereby permanently forcing any localized double-stranded regions to adopt exclusively an A-form geometry.
Because these incredibly vital messenger molecules predominantly and naturally exist as a highly flexible single strand, these highly dynamic Nucleic Acids frequently and eagerly fold completely back upon themselves to actively create a wildly diverse array of complex, functional secondary motifs. One of the most universally common structural motifs is the highly recognizable stem-loop, often called a hairpin, which simply consists of a sturdy double-helical stem securely capped by a tight loop of unpaired bases. Another highly critical and functionally important structure is the famous tetraloop, a surprisingly hyperstable, four-base hairpin loop commonly found stabilizing vital ribosomal complexes.
Even further architectural complexity in these dynamic, specialized Nucleic Acids actively arises from numerous subtle, functional structural interruptions along the backbone. Unique bulges and internal asymmetrical loops naturally occur when specific unpaired nucleotides abruptly interrupt a long double-helical tract on one or both paired strands, beautifully creating highly flexible molecular hinges or entirely novel protein recognition sites. Even more functionally complex are fascinating pseudoknots, which dynamically form when specific exposed bases situated securely within a standard hairpin loop physically reach entirely outside their local area to form strong complementary base pairs with a completely separate, distant sequence.
Slide 8 – Functional Tertiary Architectures in Specialized Nucleic Acids
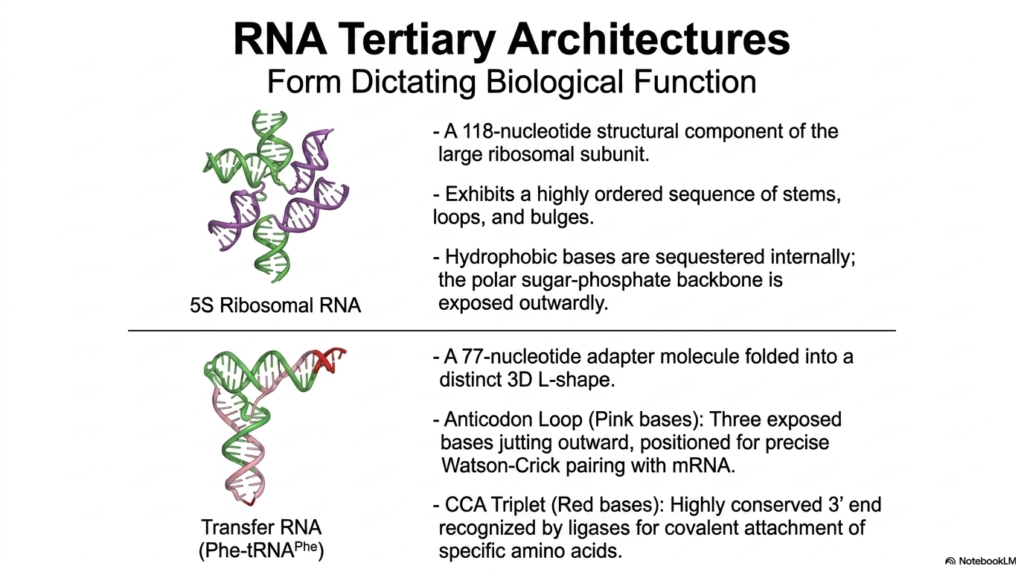
The true, absolutely staggering biochemical power of these dynamic messenger molecules becomes immediately apparent when we closely examine their intricate tertiary architecture, perfectly demonstrating the fundamental biological principle that physical form strictly dictates physiological function. Just like complex, bulky functional proteins, these specific, highly versatile Nucleic Acids can actively fold into exceptionally precise, tightly constrained three-dimensional shapes absolutely required for continued cellular survival and daily function. A totally prime, universally studied example is the vital 5S Ribosomal RNA, a critical 118-nucleotide structural component permanently residing within the large ribosomal subunit, exhibiting a highly ordered sequence of perfectly placed stems and loops.
In the incredibly intricate, highly evolved folding patterns of these purely functional Nucleic Acids, we clearly observe distinct, highly organized chemical sorting completely reminiscent of complex enzymatic proteins. Much like the dense, folded core of a functional enzyme, the highly hydrophobic bases of the critical 5S rRNA are safely and securely sequestered internally, completely hidden from the surrounding reactive water. Meanwhile, the highly polar, intensely negatively charged sugar-phosphate backbone proudly remains exposed, safely interacting directly with the highly aqueous cellular environment and actively enabling necessary stabilizing chemical interactions with ambient metallic ions.
Another absolutely spectacular, universally essential example of physical form perfectly following biochemical function in the incredible world of Nucleic Acids is the vital Transfer RNA, or tRNA. This small, highly conserved 77-nucleotide adapter molecule predictably folds into a very distinct, globally recognized three-dimensional L-shape. This highly specific, rigid architecture beautifully separates two immensely critical, completely separate functional zones. The exposed anticodon loop notably features three distinct bases jutting sharply outward to accurately read the passing genetic code. On the exact opposite physical end, the highly conserved terminal CCA triplet predictably serves as the precise, mandated attachment point for specific amino acids.
Slide 9 – The High-Fidelity Replication Machinery of Nucleic Acids
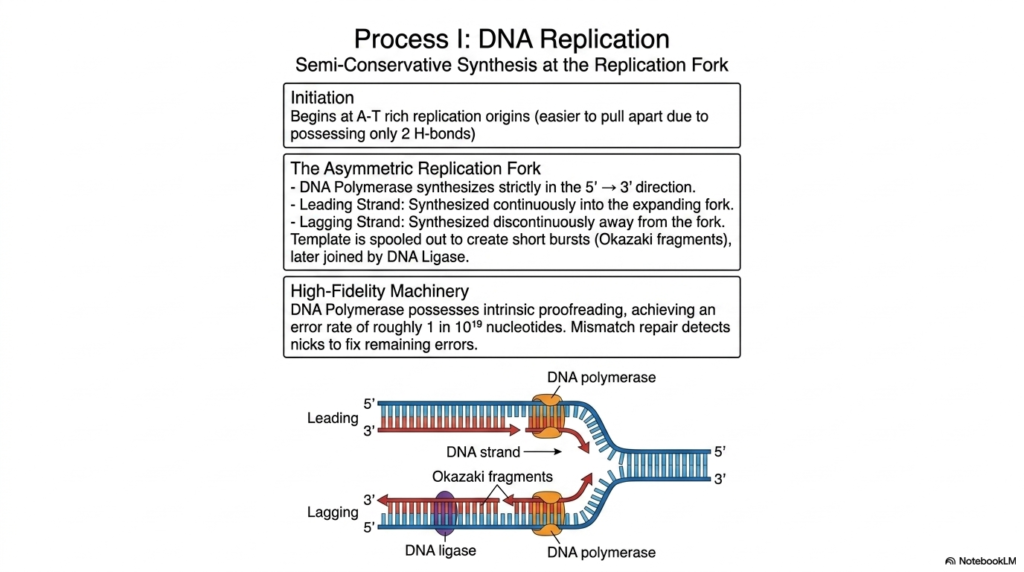
The absolute biological continuity of life depends entirely on the highly faithful, incredibly accurate duplication of our master genetic code, a globally essential cellular process known as replication. This absolutely crucial biological mechanism, heavily involving our primary storage Nucleic Acids, reliably operates via highly efficient semi-conservative synthesis, meaning that each newly formed, complete double helix contains exactly one original parent strand and exactly one entirely newly constructed daughter strand. The highly coordinated process safely begins at highly specific genetic sites called replication origins, which are heavily and typically rich in alternating adenine and thymine bases due to weaker bonding.
As the massive, tightly wound double helix vigorously unwinds, it rapidly creates a highly dynamic, structurally asymmetric replication fork. The primary, highly specialized enzyme responsible, known as DNA Polymerase, is remarkably strict and can absolutely only synthesize new complementary Nucleic Acids in a completely rigid, unyielding 5′ to 3′ chemical direction. This strict directional constraint completely creates a beautifully smooth, continuously active synthesis process for the primary leading strand, which effortlessly builds straight into the rapidly expanding fork. However, the opposing, chemically awkward lagging strand must inevitably be synthesized discontinuously, with fragments constantly moving away from the advancing replication fork.
To absolutely guarantee the pristine, long-term integrity of these globally vital Nucleic Acids, the entire complex replication machinery must be extraordinarily, unbelievably accurate. The remarkable DNA Polymerase is absolutely not merely a fast, blind builder; it actively acts as an incredibly strict, high-fidelity biological editor. It proudly possesses massive intrinsic proofreading capabilities that instantly catch and chemically correct deadly mistakes on the fly, reliably achieving an absolutely astounding, highly impressive error rate of roughly one mistake in ten billion nucleotides. Any remaining tiny nicks between the numerous Okazaki fragments are swiftly and permanently sealed by ligase.
Slide 10 – Transcription and the Processing of Messenger Nucleic Acids
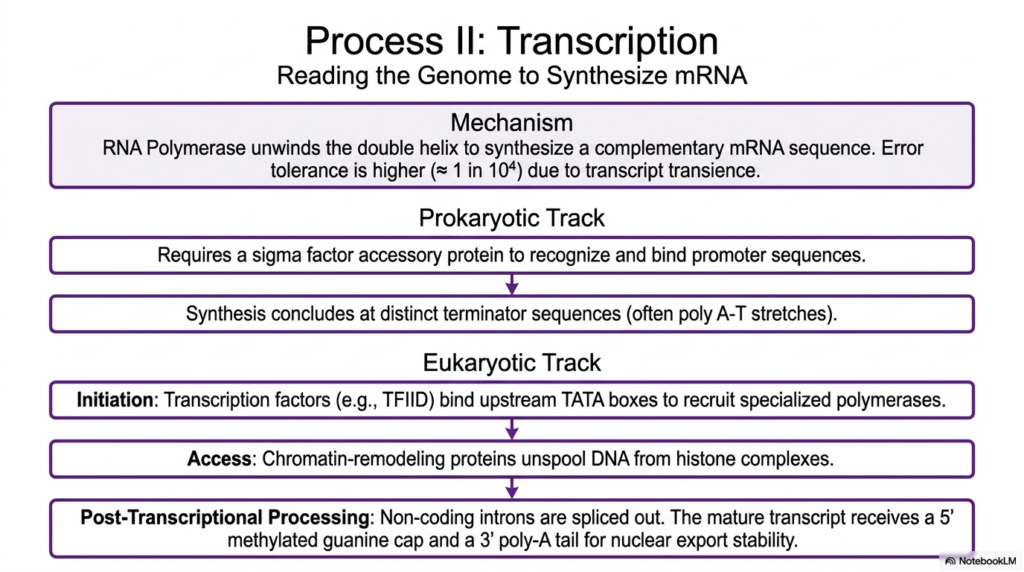
To actively and successfully utilize the heavily guarded genetic information locked away in the nucleus, eukaryotic cells must continuously undergo transcription, a highly complex process in which the rigid genomic template is read to synthesize a much more flexible messenger molecule. This incredibly vital, highly regulated task is masterfully performed by RNA Polymerase, a massive enzyme that forcefully unwinds a short, localized segment of the double helix to rapidly build a perfectly complementary messenger sequence. Because these newly synthesized, highly specialized Nucleic Acids are largely transient, the overall biological system can safely tolerate slightly higher error rates.
The active, ongoing transcription of these absolutely essential Nucleic Acids varies significantly across the vastly different biological domains of life. In the decidedly simpler, incredibly rapid prokaryotic track, the primary polymerase relies strictly on a single, vital accessory protein widely known as a sigma factor. This crucial factor actively helps the massive enzyme quickly recognize and tightly bind to highly specific promoter sequences conveniently located just upstream of a desired gene. The rapid synthesis quickly continues smoothly along the exposed template until it finally encounters highly distinct, universally recognized terminator sequences, which heavily signal the massive enzyme to detach.
By sharp contrast, eukaryotic transcription of these complex, highly vital Nucleic Acids is incredibly, intensely more heavily regulated and far more complex. It fundamentally requires multiple, massive transcription factors to simultaneously bind to upstream TATA boxes before the highly specialized polymerases can even be successfully recruited to the active site. Furthermore, incredibly powerful chromatin-remodeling proteins must aggressively unspool the tightly wound DNA from its extremely dense histone complexes to physically grant the massive enzyme the necessary physical access. Finally, the completely raw transcript undergoes massive, highly regulated post-transcriptional processing before it safely exits the protective nucleus to be read.
Slide 11 – Translation: Decoding Nucleic Acids into Functional Proteins
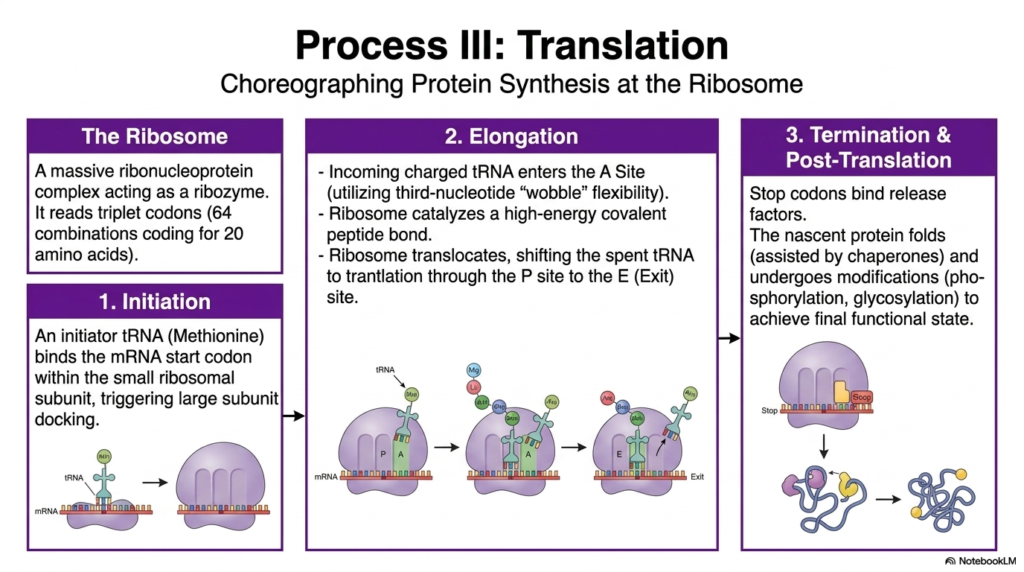
The absolute final, highly climactic phase of the universally recognized Central Dogma is translation, a beautifully, highly choreographed biochemical process in which the ancient, simple nucleotide language of Nucleic Acids is carefully and permanently converted into the highly complex, functional amino acid language of robust proteins. This incredibly intricate, vital molecular ballet takes place entirely at the mighty ribosome, a highly complex ribonucleoprotein that functions as a powerful ribozyme. The massive ribosome’s absolute primary job is to steadily read the incoming messenger RNA exactly in discrete sets of three sequential bases, widely called triplet codons.
The incredibly precise translation of critical information heavily extracted from these transient messenger Nucleic Acids proceeds steadily in three highly distinct, tightly regulated stages. It always begins with active initiation, in which a specialized initiator tRNA carrying a specific methionine tightly binds to the exact start codon on the mRNA molecule. This crucial event instantly triggers the massive ribosomal subunit to dock tightly and permanently lock the entire complex into place. Next comes rapid elongation, a highly cyclical, repetitive process in which numerous incoming charged tRNA molecules eagerly enter the ribosome’s A site to be matched.
As the massive, lumbering ribosome rapidly translocates along the length of the messenger Nucleic Acids, it systematically shifts the now completely spent, empty tRNA molecules firmly through the P site and ultimately out the open E site for immediate exit. This incredibly rapid, highly efficient elongation strictly continues until the speeding ribosome abruptly encounters a highly specific, universally recognized stop codon, which instantly triggers the final termination phase. Specialized release factors tightly bind to the stalled complex, instantly freeing the newly synthesized, fully nascent protein to begin crucial folding and ultimately achieve its final, incredibly important functional state.
Slide 12 – Applied Biochemistry and the Manipulation of Nucleic Acids

The incredibly deep, intricate understanding of structural biochemistry has enabled ambitious biological science to actively and heavily manipulate genetic material, directly giving rise to the incredibly powerful field of applied molecular biology. Modern, highly trained researchers can now routinely isolate, massively amplify, and heavily alter specific Nucleic Acids safely within the controlled laboratory. A fundamental, widely used tool in the modern scientific arsenal is the specialized restriction enzyme, which acts as incredibly precise molecular scissors to cleanly cleave complex DNA at highly specific, well-known genetic sequences, creating fragments.
When dedicated molecular researchers critically need to study highly specific, exceedingly rare genes, they almost always require millions of identical copies of those particular, highly sought-after Nucleic Acids. This is achieved efficiently and effectively primarily through the revolutionary Polymerase Chain Reaction, or PCR. This absolutely revolutionary laboratory technique massively amplifies highly specific DNA sequences by cleverly using tightly controlled, highly cyclical temperature cycles. The ingenious process involves completely denaturing the stable double helix with extremely high heat, slowly annealing extremely short, highly specific primers to target precise regions as it cools, and rapidly extending the chain.
Once fully manipulated or heavily amplified in the lab, these invisible, highly processed Nucleic Acids must be carefully analyzed and clearly visualized by scientists. Standard gel electrophoresis is widely used to separate mixed molecular fragments solely by size, forcing highly negatively charged molecules through a dense, porous gel matrix under a strong electric field. For absolute genetic precision, highly trained scientists universally use advanced nucleic acid sequencing techniques, such as the classic Sanger method, which relies on modified chain-terminating nucleotides to read the genetic code letter by letter.
Slide 13 – Diagnostic Matrix: A Comparative Analysis of Nucleic Acids
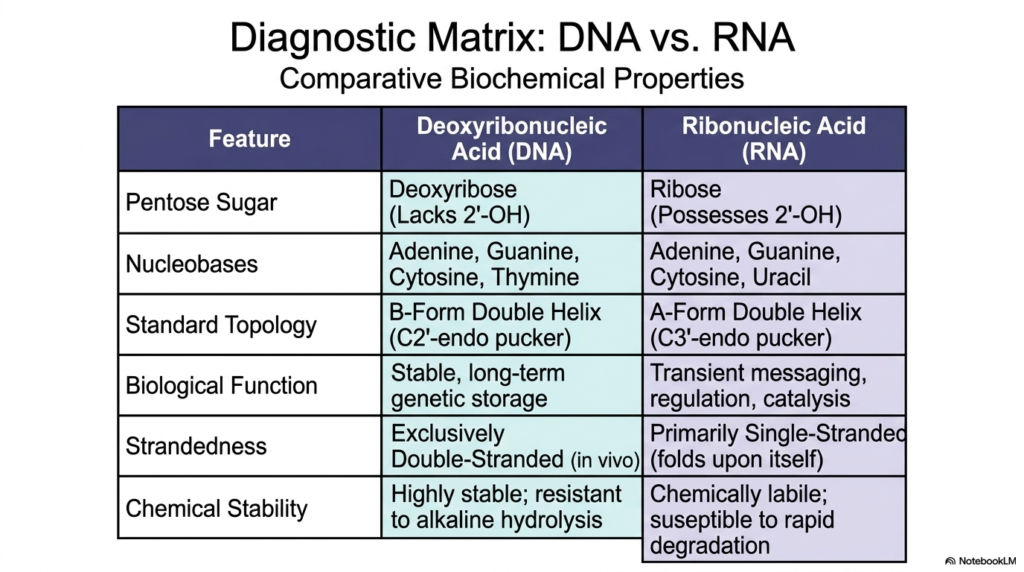
To fully summarize and accurately review the fundamental, critical chemical differences that permanently exist between the two primary biological macromolecules of life, we must rely heavily on a carefully constructed, highly comparative diagnostic matrix. The absolute most fundamental, strictly chemical distinction between these two deeply essential Nucleic Acids directly lies within the core composition of their rigid sugar backbones. Deoxyribonucleic Acid, as the long name strongly implies, relies on a remarkably sturdy deoxyribose sugar ring that notably and completely lacks a highly reactive 2′-hydroxyl group, making it exceptionally stable over long time periods.
The distinct nucleobase composition also effectively separates these highly critical, widely studied Nucleic Acids. While both entirely utilize adenine, guanine, and cytosine to encode information, stable DNA almost exclusively uses thymine to pair with adenine, whereas transient RNA entirely replaces thymine with the slightly less stable, more common uracil. Structurally speaking, the universally accepted standard topologies that actively exist within living biological systems are markedly different. DNA almost universally adopts a rigid, heavily double-stranded B-form double helix, characterized by a relaxed C2′-endo sugar pucker, whereas RNA frequently remains single-stranded.
Ultimately, the distinct, highly specific chemical structures of these completely different Nucleic Acids rigidly and precisely dictate their overarching biological purpose. Stable DNA’s total lack of an active, highly reactive 2′-hydroxyl explicitly makes it exceptionally stable and highly resistant to destructive alkaline hydrolysis, perfectly suited for its ancient evolutionary role in completely safe, ultra-long-term genetic storage. Conversely, RNA, permanently plagued by its highly reactive, entirely exposed hydroxyl group, is notoriously chemically labile and highly susceptible to rapid, targeted cellular degradation, allowing it to serve as a brilliant, transient cellular messenger.
Slide 14 – The RNA World and Structural Evolution of Nucleic Acids
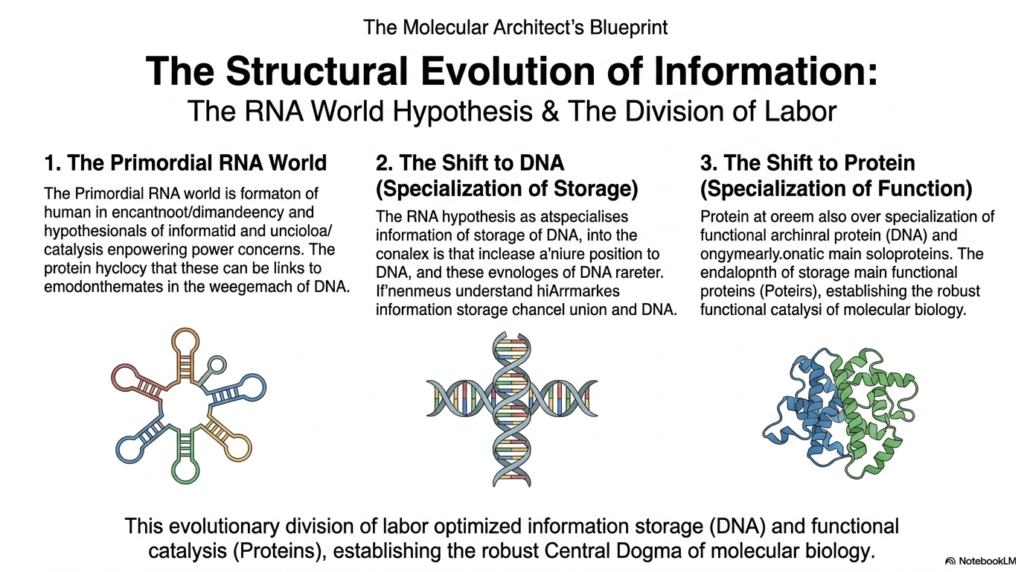
As we finally conclude our deep, highly comprehensive exploration of complex molecular architecture, we absolutely must critically consider the fascinating yet highly contested structural evolution of ancient biological information. The mysterious origin of complex life naturally presents a massive, confusing biochemical paradox regarding exactly which critical component logically came first: the complex genetic code itself or the massive enzymes completely needed to actively read it. The leading, widely accepted scientific consensus centers on the famous RNA World Hypothesis. This dominant model strongly suggests that early biological life relied entirely on highly versatile primordial RNA molecules.
These unique, anciently utilized Nucleic Acids possess the astonishing natural ability to reliably store complex genetic information while simultaneously actively catalyzing rudimentary, essential chemical reactions. Over incredibly vast, entirely unimaginable evolutionary timescales, a massive, highly beneficial structural shift completely occurred, reliably leading to an incredibly elegant, highly efficient division of cellular labor distributed directly among several distinct, newly specialized macromolecules. The highly volatile, unstable chemical nature of early RNA strongly pushed newly formed life to desperately favor a much more stable genetic repository for its increasingly precious, expanding genetic blueprints.
This incredibly massive, beautiful structural evolution strongly favored a permanent shift to using completely stable DNA, effectively transitioning the primary biological role of long-term information storage entirely to these far more stable, reliably double-stranded, chemically unreactive Nucleic Acids. The absolute final, critical stage in this completely elegant evolutionary division of biochemical labor was the permanent, total delegation of complex physical tasks. The active catalytic and vital structural roles, once rather clumsily and poorly performed by slowly folded Nucleic Acids, were entirely handed over to newly evolved, incredibly powerful, highly versatile metabolic proteins.
Please read our Content Disclaimer Statement.
Check out our social media channels: