21. Bases and Nucleotides: The Building Blocks of DNA and RNA
The microscopic world inside a single cell operates with greater precision and more complex energy-transfer mechanisms than any human-made machine. To truly understand how this cellular ecosystem thrives, one must examine its most fundamental chemical components. The core purpose of this comprehensive slide deck is to visually and textually synthesize complex biochemical structures, genetic encoding mechanisms, and metabolic pathways for college and medical school students. By exploring these intricate molecular designs in sequence, the observer will uncover the elegant chemical logic underlying how cellular life stores vital genetic information, drives powerful energy cycles, and continually sustains dynamic biochemical processes.
Slide 1: Bases and Nucleotides: The Molecular Blueprints of Cellular Life
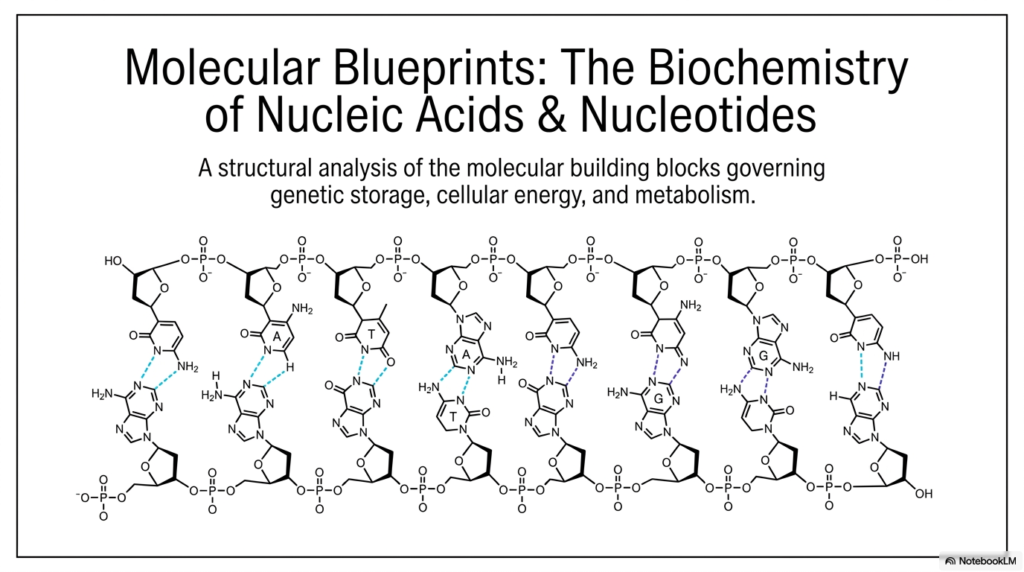
The study of life at its most fundamental level begins with understanding the intricate molecular blueprints that govern everything from cellular energy to genetic storage. For college and medical school students diving into biochemistry, mastering the structures of Bases and Nucleotides is absolutely essential. This slide introduces these foundational concepts, breaking them down into accessible, functional mechanisms. By analyzing the structural components shown in the opening schematic, one can begin to appreciate how simple atomic arrangements assemble into the magnificent double helix of DNA and the versatile strands of RNA.
Slide 1 provides a comprehensive overview of the molecular architecture that makes life possible. At the core of this structure are the nitrogenous bases, which pair specifically to hold the two strands of the nucleic acid polymer together. The diagram illustrates how these Bases and Nucleotides are connected through a continuous, rigid sugar-phosphate backbone. Hydrogen bonds between complementary bases form the rungs of this molecular ladder, ensuring remarkable stability and reliable transfer of genetic information.
Notice the specific orientation of the molecules; the alternating sugar and phosphate groups create a highly negatively charged exterior. This chemical property is crucial for interacting with water and various cellular proteins. Every single monomeric unit plays a critical role in the overall structural integrity of the macromolecule. When examining Bases and Nucleotides from a macroscopic perspective, it becomes evident that their biochemical design is exquisitely tuned for highly specific biological functions.
The sequence of these bases is never random; it represents the very code of biological life, dictating the synthesis of complex proteins and the regulation of metabolism. Understanding this overarching structure is the first step toward grasping how genetic information is accurately replicated, preserved, and expressed across countless generations of living cells.
Slide 2: Bases and Nucleotides: The Four-Level Architecture of Nucleic Acids
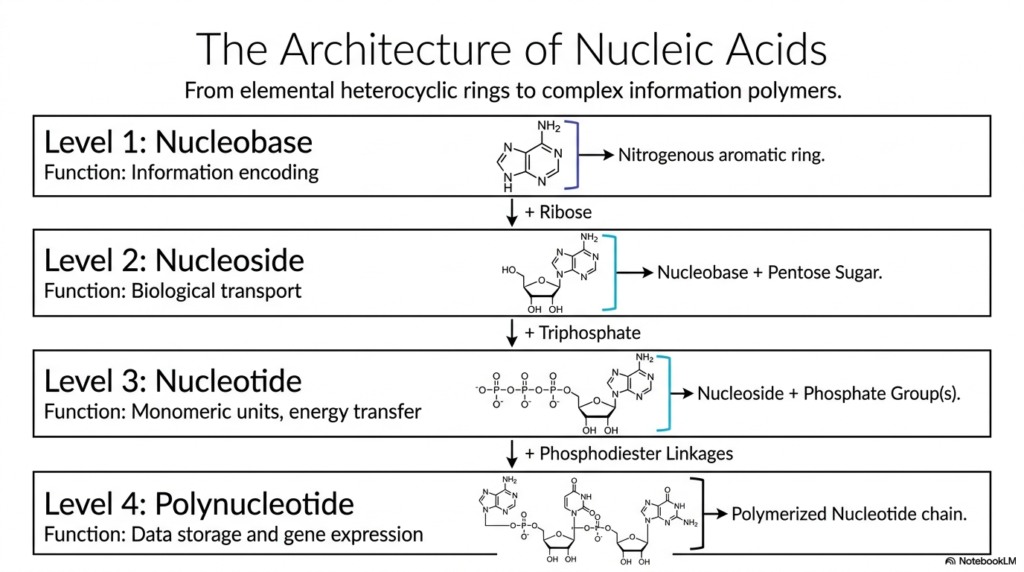
To fully comprehend the immense complexity of genetic polymers, it is vital to systematically understand their hierarchical assembly. This slide introduces the four fundamental levels of nucleic acid architecture, providing a highly logical approach to studying Bases and Nucleotides. It begins with the simplest structural component, the single nucleobase, and builds sequentially up to the incredibly long, complex polynucleotide chain. Grasping this stepwise progression clarifies the distinct chemical additions that transform a basic ring structure into a highly functional biological macromolecule capable of storing immense amounts of data.
Level 1 focuses on the nucleobase, an aromatic, nitrogen-containing heterocycle primarily responsible for encoding genetic information. Moving to Level 2, the covalent addition of a specific pentose sugar to the base creates a nucleoside. This single modification fundamentally changes its biological role, facilitating easier transport across cellular membranes. The most critical metabolic transformation occurs at Level 3, where the attachment of one or more high-energy phosphate groups yields a true, functional nucleotide.
The clear structural distinction between these unphosphorylated and phosphorylated forms of Bases and Nucleotides is fundamentally essential. The vital addition of a phosphate group provides the thermodynamic energy required for vital cellular processes and rapid enzymatic polymerization. Finally, Level 4 depicts the massive polynucleotide, in which individual nucleotides are chemically linked via robust phosphodiester bonds to form an extended chain.
This polymerized sequence is the ultimate functional form responsible for vast data storage and dynamic gene expression within the cell. By studying these four structural levels, students can clearly see how the basic organic chemistry of Bases and Nucleotides ultimately orchestrates the vast complexity of human life. Each specific chemical modification serves a precise, indispensable biological purpose.
Slide 3: Bases and Nucleotides: Decoding Purines and Pyrimidines
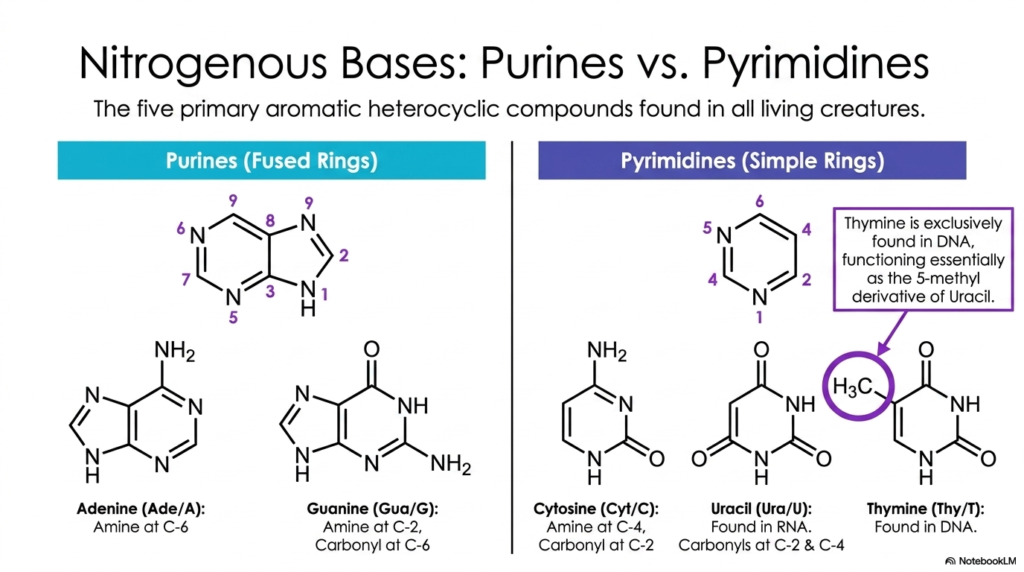
At the mechanical heart of genetic coding lies a specific, highly conserved set of aromatic heterocycles. This slide details the structural classification of the five primary nitrogenous bases found in all living organisms, a core topic in the study of Bases and Nucleotides. These organic compounds are chemically divided into two distinct families based on their ring structures: the double-ringed purines and the single-ringed pyrimidines. Understanding the specific atomic arrangements of these molecules is paramount, as their unique geometric shapes dictate how they physically interact.
The larger purines, adenine and guanine, are characterized by a fused bicyclic structure. Adenine has an amine group at C-6, while guanine has a reactive amine at C-2 and a carbonyl oxygen at C-6. In stark contrast, the pyrimidines—cytosine, uracil, and thymine—are simpler, single six-membered rings. The subtle chemical variations among them are striking. For example, thymine functions essentially as the protected 5-methyl derivative of the unstable uracil.
The strategic, evolutionary placement of these methyl, amine, and carbonyl functional groups on Bases and Nucleotides perfectly enables the specific hydrogen-bonding patterns required for highly accurate DNA replication. A fascinating aspect of this biochemical design is the exclusive biological distribution of certain bases. While adenine, guanine, and cytosine are ubiquitous in both DNA and RNA, thymine is exclusive to DNA, and uracil is exclusive to RNA.
This biochemical distinction is highly protective, chemically shielding the permanent genome from frequent mutagenic errors. For students mastering the intricate biochemistry of Bases and Nucleotides, memorizing these specific ring structures and their functional groups provides the vital key to unlocking the physical rules of the genetic code and cellular fidelity.
Slide 4: Bases and Nucleotides: Stabilizing the Furanose Sugar Backbone
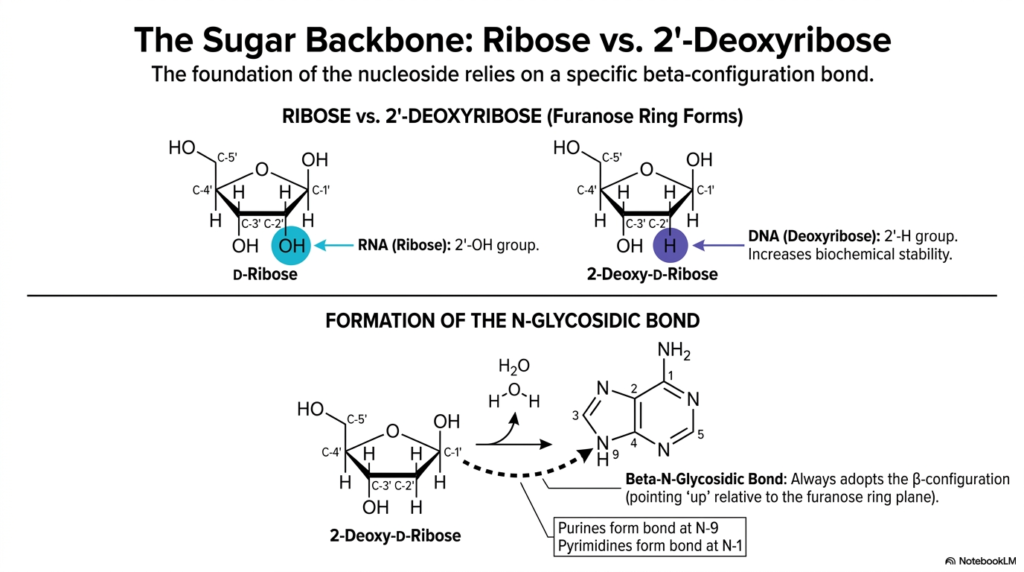
The long-term structural stability of genetic material relies heavily on the specific type of sugar molecule physically anchoring the polymer. This slide examines the critical biochemical differences between ribose and 2′-deoxyribose, the five-carbon pentose sugars that form the continuous backbone of Bases and Nucleotides. While the internal nitrogenous bases encode the genetic data, the external sugar absolutely dictates the molecular stability and functional identity of the entire macromolecule.
Understanding these subtle chemical variations is crucial to understanding why DNA is perfectly suited for long-term data storage, whereas RNA is strictly used for short-term, dynamic cellular tasks. The defining structural difference between these two furanose rings lies at the critical 2′-carbon position. Ribose, predominantly found in RNA, possesses a highly reactive 2′-hydroxyl (-OH) group. In stark contrast, 2′-deoxyribose, found exclusively in DNA, entirely lacks this oxygen atom, possessing only a single hydrogen atom at the 2′ position.
This seemingly minor absence of a single oxygen atom in these specific Bases and Nucleotides profoundly increases the overall biochemical stability of the DNA polymer. It highly protects the double helix from rapid, destructive alkaline hydrolysis. Additionally, the slide beautifully illustrates the enzymatic formation of the crucial N-glycosidic bond, the covalent linkage intimately connecting the sugar ring to the specific nucleobase.
Through an energetic condensation reaction, a single water molecule is eliminated, securely attaching the base to the 1′-carbon. Notably, this specific linkage in Bases and Nucleotides always chemically adopts the rigid beta-configuration. By deeply understanding the chemical properties of ribose and deoxyribose, students gain a profound appreciation for the elegant, protective structural logic inherent in cellular genetics.
Slide 5: Bases and Nucleotides: Structural Differentiation and Nomenclature
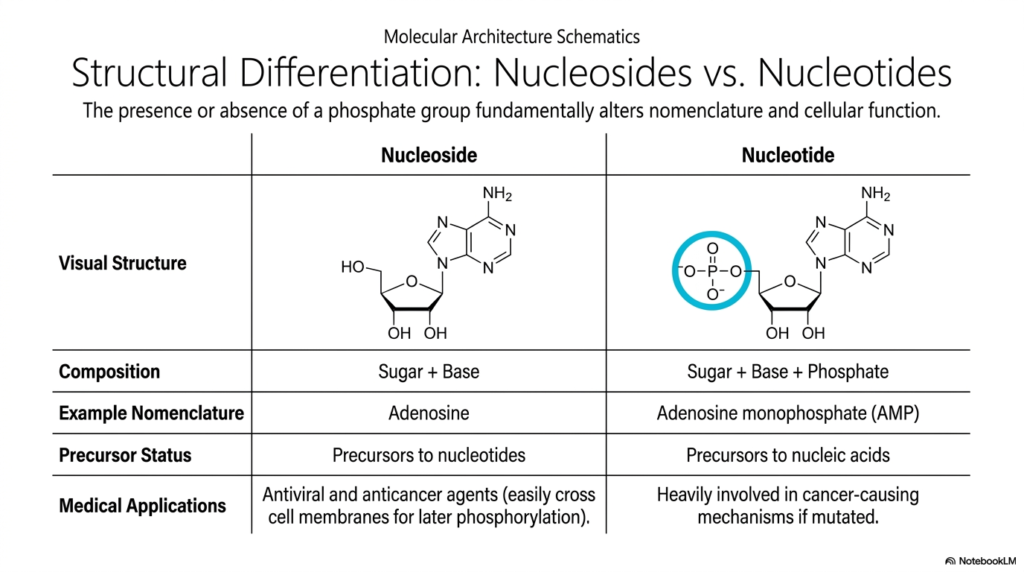
Precision in biochemical terminology is absolutely essential for avoiding critical diagnostic errors in both academic research and modern clinical settings. This slide clarifies the fundamental structural and functional differences between nucleosides and nucleotides, a frequent source of confusion when first studying Bases and Nucleotides. The singular defining factor is simply the physical presence or complete absence of an attached phosphate group.
Remarkably, this single molecular modification drastically alters the compound’s chemical nomenclature, primary cellular location, and overall physiological function. A nucleoside consists purely of a raw pentose sugar covalently bonded to a nitrogenous base, clearly seen in the visual example of adenosine. Without a highly charged phosphate group, nucleosides act primarily as biologically inactive structural precursors. However, they hold immense, life-saving medical significance in modern pharmacology.
Many antiviral and anticancer pharmaceutical agents are deliberately synthesized as nucleosides because their uncharged, neutral nature allows them to readily cross lipid membranes. Once safely inside the targeted cell, endogenous cellular kinases aggressively phosphorylate these therapeutic drugs, rapidly converting them into fully active Bases and Nucleotides. These newly armed molecules can then mechanically disrupt dangerous viral replication or forcefully halt aggressive tumor growth.
In sharp contrast, the enzymatic addition of one or more dense phosphate groups creates a true nucleotide, such as adenosine monophosphate (AMP). This critical phosphorylation imparts a massive negative charge, physically trapping the active molecule within the cell membrane. Within the vast ecosystem of Bases and Nucleotides, these true phosphorylated units serve as the direct, highly energetic monomers desperately required for continuous DNA and RNA synthesis.
Slide 6: Bases and Nucleotides: Powering the Cell with Acid Anhydride Bonds
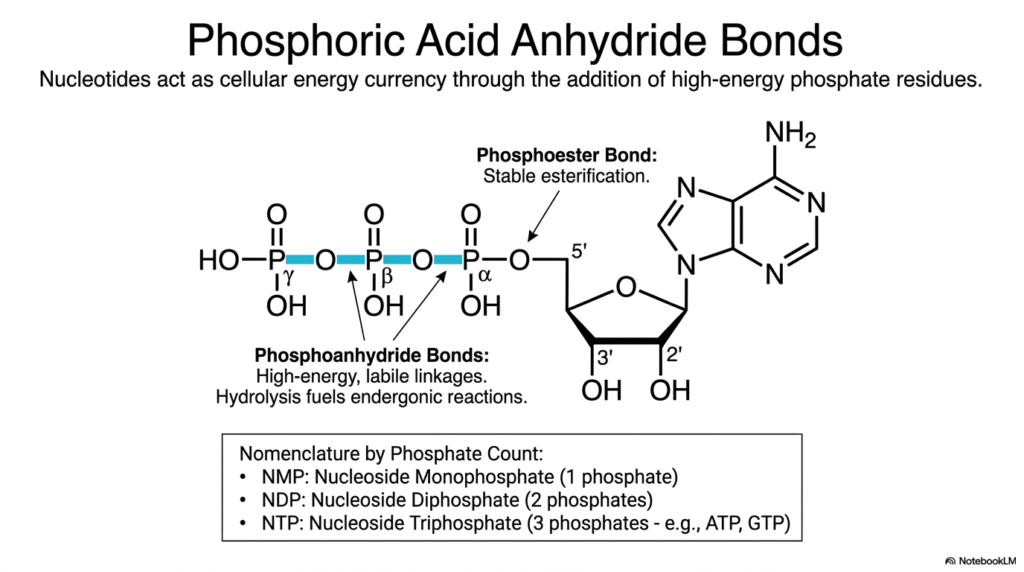
Thermodynamic energy is the universal currency of cellular life, and the vast cellular economy operates almost entirely on the immense energetic potential stored within very specific molecular bonds. This slide dives directly into the powerful mechanism by which specific nucleotides act as the primary cellular energy currency. It highlights a spectacularly crucial, life-sustaining metabolic function of Bases and Nucleotides that extends far beyond mere static genetic storage.
By closely examining the specific types of covalent linkages binding multiple phosphate residues together, one can clearly understand how energetic molecules powerfully capture and transfer energy. The detailed schematic illustrates a single nucleoside covalently attached to a dense chain of three clustered phosphate groups. The very first phosphate is securely linked to the sugar ring via a highly stable, low-energy phosphoester bond. However, the subsequent attached phosphates are joined entirely by highly unstable, high-energy phosphoanhydride bonds.
Because these massive, negatively charged phosphate groups chemically repel one another, physically packing them together creates immense coiled chemical potential energy. When studying the dynamic metabolic actions of Bases and Nucleotides, it is crucial to recognize that the rapid enzymatic hydrolysis of these labile linkages releases an explosive burst of energy. This energetic release powerfully drives muscle contraction, rapid nerve impulse propagation, and complex chemical synthesis.
Furthermore, the strict scientific nomenclature dynamically shifts based on the precise numerical count of phosphate groups attached. The continuous cycle of rapidly building and explosively breaking these volatile phosphoanhydride bonds represents the beating heart of cellular respiration. A thorough comprehension of how energy is perfectly stored and liberated within Bases and Nucleotides provides the fundamental basis for mastering all downstream physiological processes.
Slide 7: Bases and Nucleotides: Constructing the Phosphodiester Backbone
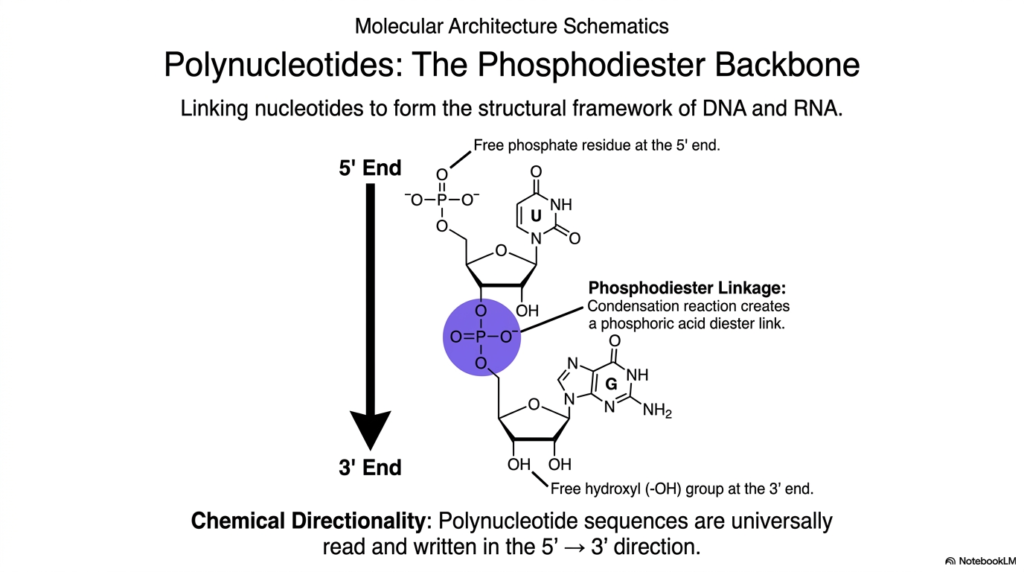
The critical metabolic transition from hundreds of individual, free-floating monomeric units to a singular, functional, information-carrying polymer requires a highly specific and exceptionally strong chemical linkage. This slide illustrates the continuous formation of the resilient phosphodiester backbone, the rigid structural framework that strongly links individual building blocks into long, continuous DNA and RNA strands.
Understanding exactly how distinct Bases and Nucleotides are permanently polymerized is critical to fully comprehending the incredibly complex mechanisms of genetic replication, rapid transcription, and life-saving enzymatic repair. The immense physical strength of this continuous covalent backbone strongly protects the incredibly fragile genetic code securely stored within the internal array of nitrogenous bases. Rapid cellular polymerization occurs via a targeted condensation reaction that cleanly creates a phosphoric acid diester link.
This robust covalent bond is violently forged between the 5′-phosphate group of one incoming energetic nucleotide and the completely free 3′-hydroxyl (-OH) group of the preceding, anchored nucleotide on the slowly growing polymer chain. When actively studying the biochemistry of Bases and Nucleotides, it is absolutely essential to recognize the precise anatomical locations of these highly reactive functional groups. Massive enzymes like DNA polymerase can only construct the entire macromolecule by continuously catalyzing this highly specific, directional chemical junction.
This strict, uniform method of linkage imparts a vital, universally recognized property to the resulting polynucleotide: strict chemical directionality. Biological systems universally read, copy, and rapidly synthesize these massive polymers of Bases and Nucleotides exclusively in the 5′ to 3′ direction. Mastery of how this incredibly resilient backbone is structurally formed is absolutely foundational for any student delving deeply into the mechanical realities of molecular biology.
Slide 8: Bases and Nucleotides: The Strict Rules of Spatial Constraints
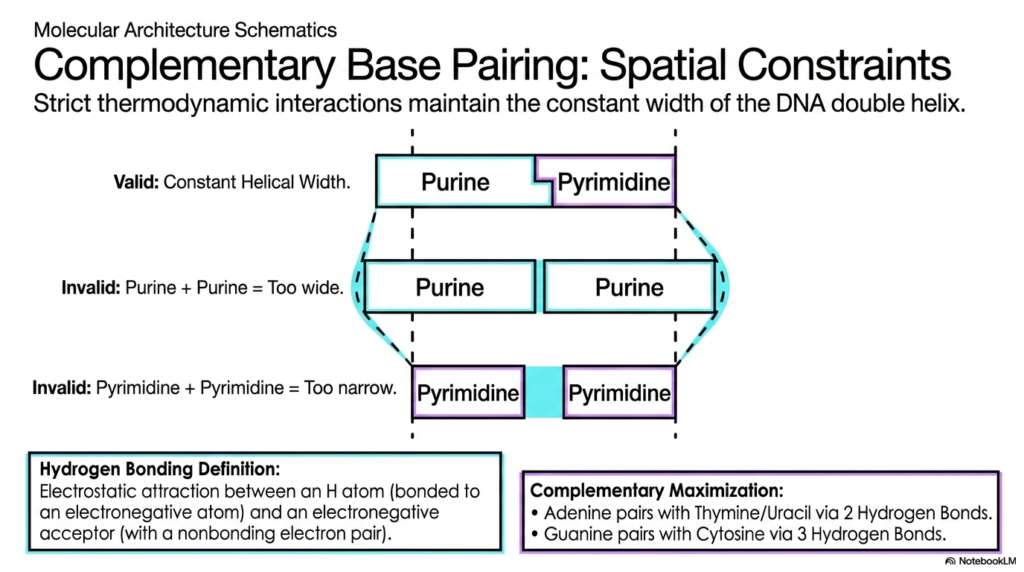
The elegant, universally recognized geometric symmetry of the massive DNA double helix is absolutely not a random biological occurrence, but rather the direct result of incredibly strict physical and thermodynamic laws. This slide thoroughly explores the unyielding spatial constraints that govern complementary base pairing, clearly explaining why specific Bases and Nucleotides must pair in highly restrictive combinations.
For dedicated medical and biological students, a deep understanding of these rigid physical boundaries clarifies exactly how dangerous mutations arise when these geometric rules are violently violated. The visual diagram beautifully demonstrates that to maintain a perfectly constant, highly uniform helical width, a massive double-ringed purine must absolutely always pair with a much smaller, single-ringed pyrimidine. If two bulky purines were to erroneously pair, the resulting rigid structure would instantly become far too wide.
This fatal error would actively cause a highly damaging structural bulge in the delicate DNA backbone. Conversely, if two tiny pyrimidines paired together, the internal spatial gap would simply be too narrow, violently pinching the entire double helix deeply inward. These unyielding spatial constraints ensure that the interacting Bases and Nucleotides span the entire internal geometric diameter of the double helix without physically distorting the structural framework.
Within these harsh spatial constraints, specific thermodynamic hydrogen bonding further brutally enforces pairing fidelity. By rigorously enforcing both perfect spatial uniformity and maximum thermodynamic hydrogen-bonding efficiency, biological nature has successfully designed an inherently brilliant, highly self-correcting data storage mechanism. Grasping the precise physical logic of how Bases and Nucleotides fit together flawlessly is essential to truly understanding the incredibly high fidelity of genetic replication.
Slide 9: Bases and Nucleotides: Detailed Structural Anatomy of Base Pairs
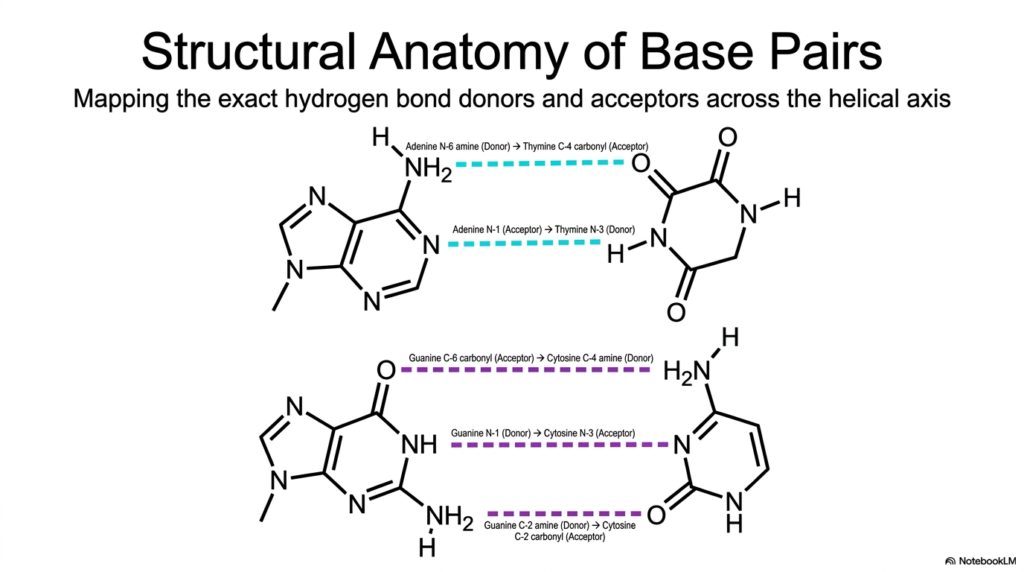
To truly appreciate the breathtaking fidelity of complex genetic replication, an astute observer must rapidly zoom in directly to the atomic level and scrutinize the exact chemical interactions that bridge the two massive DNA strands. This slide provides an incredibly detailed, highly accurate structural anatomy of individual base pairs, meticulously mapping the precise molecular hydrogen-bond donors and acceptors along the internal helical axis.
For diligent students heavily studying the specific properties of Bases and Nucleotides, accurately memorizing this specific, complex molecular topography is undeniably crucial. It perfectly explains the immense thermodynamic stability of the entire double helix and precisely reveals the exact mechanism of action for various life-saving DNA-binding drugs. In the classic Adenine-Thymine (A-T) base pair, exactly two highly distinct, thermodynamic hydrogen bonds are safely formed.
The prominent N-6 amine group of massive Adenine serves as the primary hydrogen donor, physically reaching across the central axis to form a strong bond with the highly electronegative C-4 carbonyl acceptor of smaller Thymine. This exact, flawless alignment of internal donors and acceptors between these highly specific Bases and Nucleotides beautifully ensures that only precise molecular pairs can successfully form a highly stable, energetically favorable interaction without instantly causing catastrophic steric hindrance.
The powerful Guanine-Cytosine (G-C) pairing is even more structurally robust, actively utilizing exactly three strong hydrogen bonds. Because these G-C pairs forcefully contain exactly three strong hydrogen bonds compared to the two found in fragile A-T pairs, massive genomic regions heavily rich in these specific Bases and Nucleotides actively possess a significantly higher melting temperature. This dense internal network is the true atomic basis of the reliable genetic code.
Slide 10: Bases and Nucleotides: Expanding Beyond DNA into Cellular Metabolism
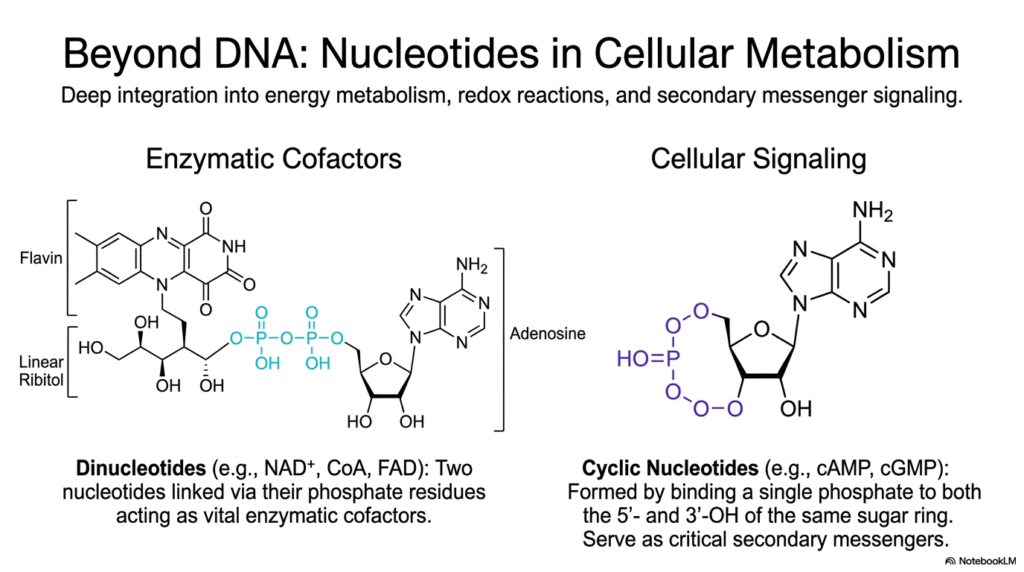
While the primary role of specific nucleotides in massive genetic storage is universally recognized across the biological sciences, their highly critical, life-sustaining functions actively extend far beyond the narrow physical boundaries of the structural double helix. This crucial slide aggressively expands the biochemical perspective, meticulously detailing how diverse nucleotides are deeply integrated into explosive energy metabolism, complex cellular redox reactions, and highly intricate secondary messenger signaling cascades.
By actively exploring the massively diverse cellular roles forcefully undertaken by varied Bases and Nucleotides, observant students will quickly discover that these unique molecules are essentially the true master metabolic regulators of all active cellular physiology. One highly critical biological function prominently highlighted here is their vital structural role as immense, complex enzymatic cofactors. The immense molecular structures of Flavin Adenine Dinucleotide (FAD), Nicotinamide Adenine Dinucleotide (NAD+), and Coenzyme A (CoA) all physically feature a dense adenosine nucleotide intimately integrated directly into their core architecture.
In these incredibly massive, complex dinucleotides, exactly two active Bases and Nucleotides are covalently linked directly via their reactive phosphate residues. This unique structural arrangement actively produces essential cellular coenzymes that serve as highly efficient electron carriers deep within the busy Krebs cycle. Furthermore, the detailed slide effectively illustrates the rapid enzymatic formation of volatile cyclic nucleotides, such as active cyclic AMP (cAMP).
In the vast, interconnected internal ecosystem of active Bases and Nucleotides, these highly specialized cyclic variants fiercely serve as incredibly critical, rapidly moving secondary messengers. They actively relay massive chemical signals from external protein hormone receptors deep into the dense cytoplasm, instantly altering vast profiles of enzymatic activity.
Slide 11: Bases and Nucleotides: De Novo Biosynthesis Metabolic Pathways
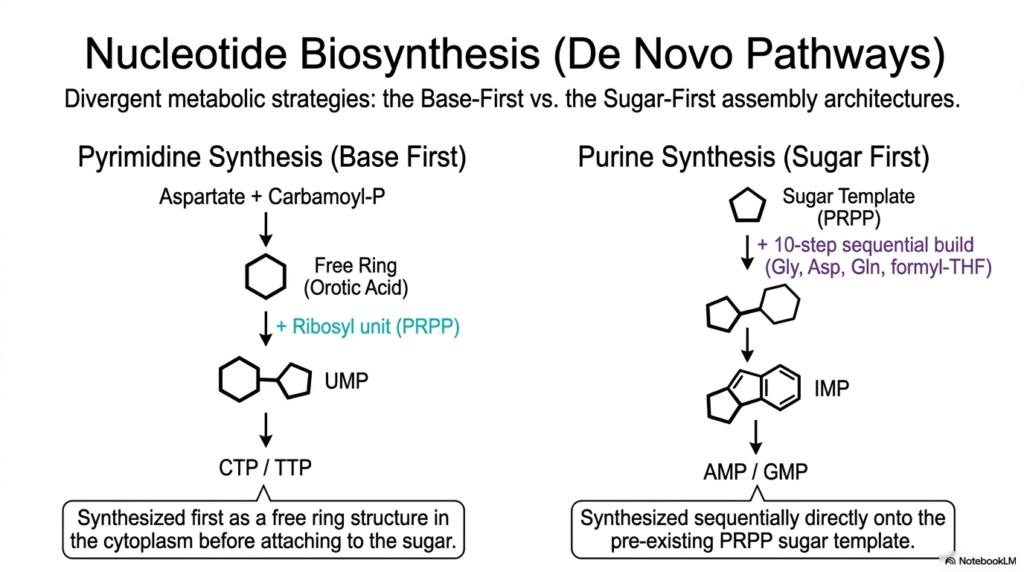
To actively sustain incredibly rapid, highly continuous cellular division and massively active internal metabolism, thriving biological systems must violently manufacture their own complex molecular building blocks directly from raw, simple atomic scratch. This highly detailed slide effectively outlines the vastly divergent, complex metabolic strategies actively utilized in essential de novo nucleotide biosynthesis. It vividly contrasts the unique Base-First assembly of dense pyrimidines with the completely opposite Sugar-First biological construction of massive purines.
Deeply understanding precisely how rapidly dividing cells aggressively synthesize vast quantities of Bases and Nucleotides is highly relevant to active medical students. These highly active, dense metabolic pathways are frequently the absolute prime therapeutic targets for powerful antimetabolite chemotherapy drugs heavily designed to rapidly halt violently unchecked, massive cancerous cellular proliferation. The detailed metabolic schematic aggressively reveals a truly fascinating, massive evolutionary biochemical divergence in synthetic logic.
Pyrimidine cellular synthesis actively utilizes a truly fascinating “Base-First” strategy. Simple chemical precursors are initially assembled directly into a free, completely unattached basic ring structure actively known as simple orotic acid deep in the liquid cytoplasm. Only after the entire basic ring is fully structurally constructed is it finally securely attached to the active ribosyl sugar. This completely step-wise process is highly unique among all synthesized Bases and Nucleotides.
In incredibly stark contrast, massive purine synthesis actively relies heavily on a complex “Sugar-First” architecture. Through a highly complex, highly energetic 10-step sequential biochemical pathway, raw organic materials are added, piece by piece, directly onto the existing sugar ring. The diverse metabolic mechanisms required to actively construct Bases and Nucleotides highlight astonishing evolutionary chemical complexity.
Slide 12: Bases and Nucleotides: Epigenetics and Mutagenic Chemical Deamination
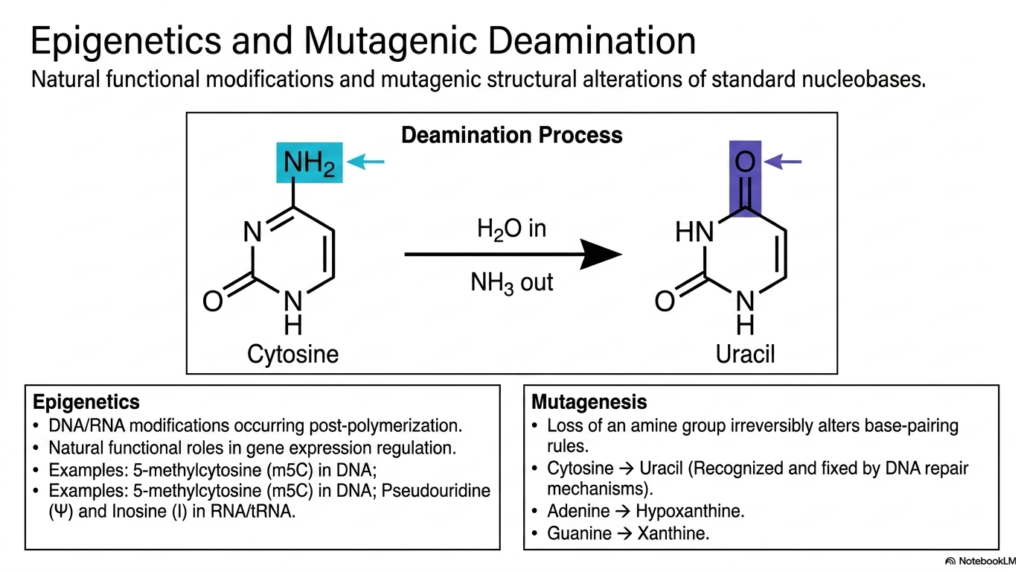
The massive genetic sequence safely stored inside the nucleus is absolutely not a static, completely unchanging manuscript; it is an incredibly dynamic, living code constantly subject to both intentional regulatory biochemical modifications and highly dangerous, spontaneous chemical damage. This slide thoroughly explores the fascinating dual processes of natural epigenetics, which exist directly alongside highly destructive mutagenic deamination. It highlights exactly how distinct structural alterations strongly impact overall genomic integrity.
For focused students studying human genetics and clinical oncology, a deep understanding of how delicate Bases and Nucleotides are chemically modified post-polymerization is critical to grasping how cells biologically differentiate, slowly age, and often become highly malignant. The absolute most common and incredibly perilous spontaneous structural mutation is the rapid, dangerous chemical deamination of fragile cytosine. Through a simple, destructive hydrolytic reaction with water, the exposed amine group is violently lost, irreversibly converting the molecule into the strange uracil.
Because volatile uracil naturally pairs with completely different partners, this destructive loss fundamentally and dangerously alters the strict base-pairing rules of the structurally affected Bases and Nucleotides. Fortunately, highly sophisticated, massive cellular DNA repair enzymes continually, aggressively scan the entire fragile genome to rapidly recognize and violently excise these highly dangerous, misplaced uracil residues. However, not all natural chemical modifications are inherently destructive.
The detailed slide explains functional epigenetics—the highly purposeful, carefully regulated enzymatic addition of dense chemical tags to massive DNA strands to precisely regulate specific gene expression. RNA actively utilizes highly modified bases and nucleotides, such as massive pseudouridine, to structurally regulate translation efficiency. These markers add a massive, vital layer of complex control.
Slide 13: Bases and Nucleotides: The Expanding Frontiers of Synthetic Medicine
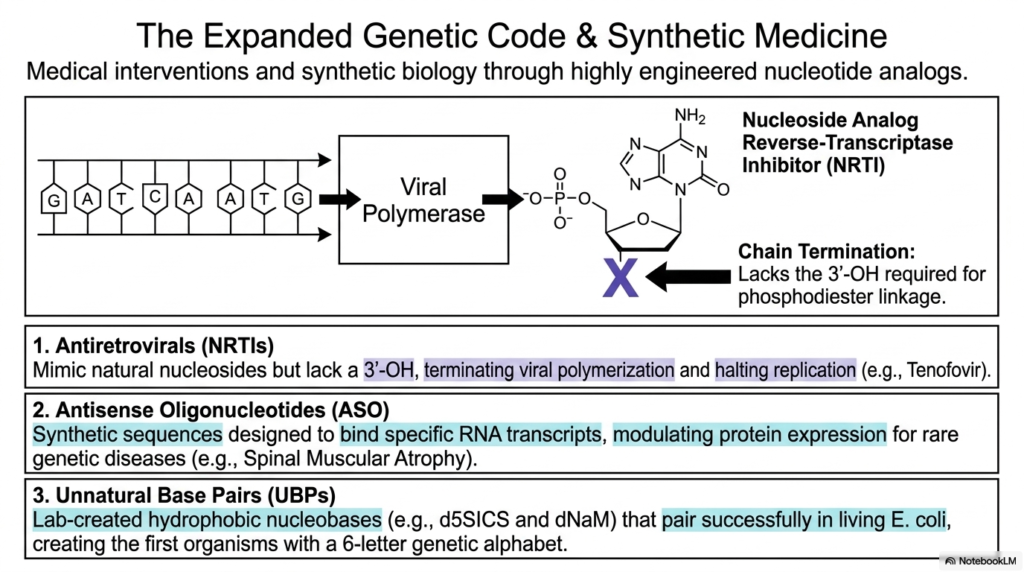
Humanity’s incredible scientific mastery of complex molecular biology has advanced to the astonishing point where researchers can deliberately redesign the fundamental building blocks of cellular life to actively cure deadly diseases. This highly exciting slide delves directly into the massively expanded genetic code and modern synthetic medicine, highly highlighting groundbreaking medical interventions actively created through intensely engineered nucleotide analogs.
By actively, highly aggressively manipulating the raw foundational chemistry natively found within Bases and Nucleotides, brilliant scientific researchers and clinical pharmacologists have massively developed truly revolutionary, highly effective clinical treatments. One highly prime, incredibly successful clinical example is the widespread medical use of active Nucleoside Analog Reverse-Transcriptase Inhibitors (NRTIs), such as the life-saving Tenofovir, widely used to aggressively combat deadly HIV.
These incredible synthetic therapeutic drugs perfectly and cleanly mimic highly natural nucleosides but lack the biologically crucial 3′-hydroxyl group. When the violently invasive viral polymerase makes highly mistaken insertions of these perfectly engineered Bases and Nucleotides directly into the actively growing, dangerous viral DNA chain, the complete, absolute lack of a reactive 3′-OH aggressively and violently prevents any further phosphodiester linkage. This instantly results in complete chain termination, highly effectively halting all dangerous viral replication.
The powerful medical applications of advanced synthetic biochemistry extend even further into complex Antisense Oligonucleotides (ASOs). Through the highly targeted, clinical application of these completely artificial Bases and Nucleotides, modern medicine can literally, safely, and physically intercept destructive transcripts in real-time. The incredible structural plasticity powerfully demonstrates that life’s complex molecular language is entirely, wonderfully malleable.
Slide 14: Bases and Nucleotides: Standardized IUPAC Degenerate Base Nomenclature
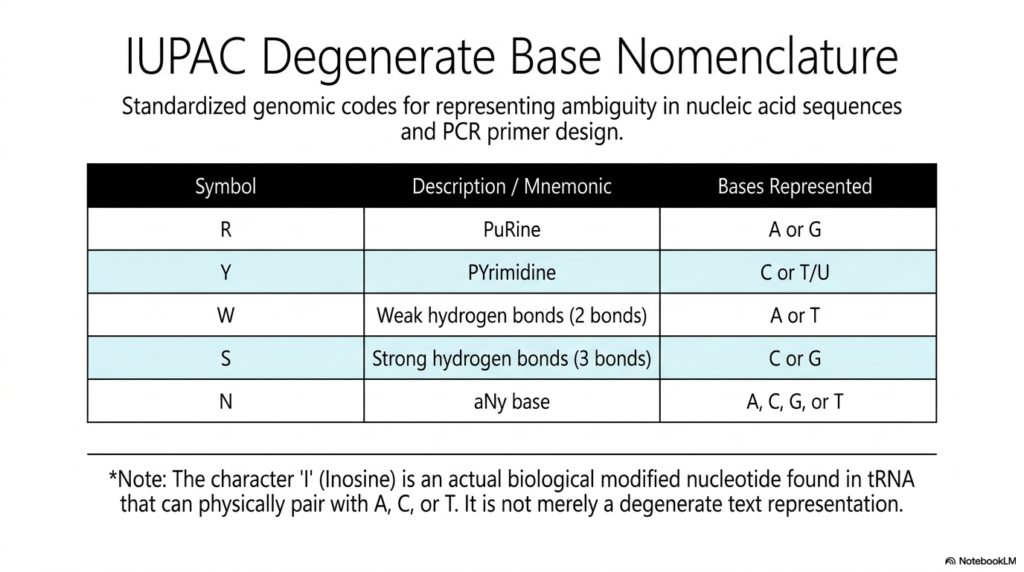
In the highly rigorous, practical, daily, real-world laboratory practice of massive computational genomics and active molecular biology, recorded genetic sequences are almost never perfect or entirely, cleanly unambiguous. This practical slide introduces the vital standardized IUPAC degenerate base nomenclature, a highly formalized, universally accepted system specifically designed to represent structural ambiguity in vast nucleic acid sequences.
For anyone actively working extensively in modern bioinformatics or directly conducting heavy laboratory genetics, perfectly memorizing these highly specific, vital text codes that meticulously classify various Bases and Nucleotides is an absolute, non-negotiable practical necessity. The highly standardized, universal table clearly provides strict mnemonic codes that perfectly represent multiple potential physical bases at one single, specific genomic position. For a clear example, the distinct symbol “R” universally stands for the massive purine.
Conversely, “Y” strictly represents a tiny Pyrimidine, perfectly signifying either active Cytosine (C) or structural Thymine (T). This highly systematic, globally recognized shorthand allows dedicated scientists to neatly and accurately summarize massive genetic variations without the inefficiency of manually writing out sprawling arrays of thousands of individual Bases and Nucleotides. Other highly critical text designations actively rely heavily on the specific physical properties of the internal hydrogen bonds.
It is practically important to always note one major exception: the unique character “I” actively represents the biological Inosine. Unlike all other mere text placeholders, massive Inosine is an actual, physically heavily modified biological nucleotide naturally found actively functioning in vast tRNA. This strictly standardized nomenclature beautifully bridges the massive gap.
Slide 15: Bases and Nucleotides: The Complete Unified Molecular Ecosystem
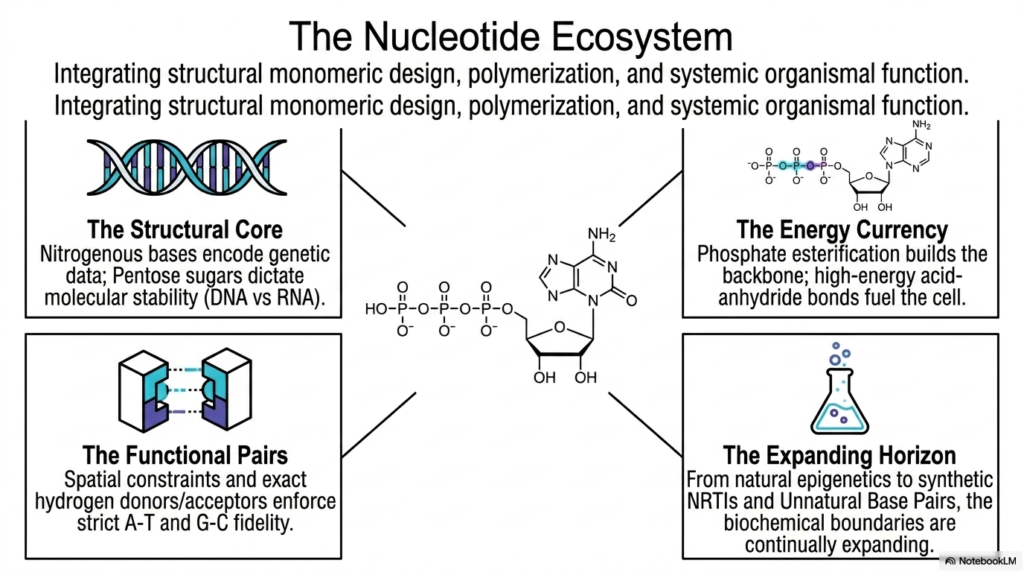
The rigorous, intensive study of complex biological biochemistry ultimately aims to brilliantly synthesize hundreds of highly discrete structural facts entirely into one single, massive unified understanding of total biological function. This massive final summarizing slide perfectly and powerfully summarizes the entire “Nucleotide Ecosystem,” violently integrating fundamental monomeric biological design, explosive polymerization, and massive systemic organismal function into a single cohesive framework.
By aggressively synthesizing the immense biological principles covered throughout this massive deck, astute students can fully appreciate the breathtaking structural versatility exhibited by all Bases and Nucleotides. The entire massive biological ecosystem is completely physically anchored heavily by the rigid structural core, where massive nitrogenous bases fiercely encode vast libraries of pure genetic data.
Operating entirely within this incredibly dense biological core are the strict functional pairs, in which spatial constraints and precise hydrogen-bond donors flawlessly enforce complete pairing fidelity. This exact, pristine geometric matching of billions of Bases and Nucleotides virtually guarantees that crucial biological information is flawlessly, flawlessly preserved across thousands of vast generations. Alongside vast genetic storage, the unified ecosystem strongly emphasizes a vast energy currency.
The capacity of incredibly versatile Bases and Nucleotides to flawlessly act simultaneously completely as both a permanent information archive and a wildly high-energy cellular battery is astonishing. From completely natural epigenetic biological modifications to the incredibly complex synthetic clinical design of modern medical NRTIs, the boundaries of biochemistry are continually expanding every single day across the global scientific world.
Please read our Content Disclaimer Statement.
Check out our social media channels: